

Les approches expérimentales
L’Essai Randomisé contrôlé (ERC) traduit de l’anglais Randomized controlled trial (RCT) est également appelé « approche expérimentale ».
En 1971, le psychologue américain Donald T. Campbel (qui se définit lui-même comme « évaluateur par accident ») rêve lors de son discours d’introduction au congrès de l’Association Américaine de Psychologie, d’une société expérimentatrice :

« Une société expérimentatrice sera celle qui expérimentera vigoureusement des solutions à des problèmes récurrents, qui fera des évaluations déterminées et multidimensionnelles des résultats et qui s’orientera vers de nouvelles alternatives lorsque les évaluations démontrent qu’une réforme a été inefficace voire dangereuse. Cette société n’existe pas à ce jour. »
eval.fr
En 2003, lors d’une conférence de la Banque Mondiale sur l’efficacité de l’aide, Esther Duflo déclare :
« De la même manière que les évaluations randomisées ont révolutionné la médecine au 20ème siècle, elles ont le potentiel de révolutionner les politique sociales au 21ème. »

Pour certains acteurs, la définition de l’évaluation d’impact s’affiche plus étroite que celle proposée par le CAD.
Selon eux, une évaluation d’impact ne peut être rigoureuse qu’en présence d’un scénario contrefactuel. Voir par exemple la définition de l’USAID ci-dessous.
« Les évaluations d’impact mesurent le changement dans un effet de développement qui est attribuable à une intervention définie ; les évaluations d’impact sont basées sur des modèles de cause et d’effet et demandent un scénario contrefactuel crédible et rigoureusement défini pour contrôler les facteurs autres que l’intervention qui pourraient expliquer les changements observés. »
USAID
Ainsi la dénomination « évaluation d’impact » ne s’appliquerait que pour les études permettant de mesurer les effets strictement attribuables à une intervention grâce à un comparaison avec une modélisation de la situation en absence d’intervention (le contrefactuel).

eval
Pourquoi RCT ?
TRIAL : l’étude porte sur une expérimentation dans le sens ou les effets du programme ou de la politique publique ne sont pas encore connus
CONTROLLED : l’expérience doit être contrôlée sur le temps du programme et requiert ainsi une constance méthodologique
RANDOMIZED : aléatoire, c’est à dire avec la mise en place de tirages au sort. Il s’agit de dégager une population similaire et terme de caractéristiques observables (âge, revenu, niveau d’éducation, etc.) mais aussi non-observables (motivation, détermination, etc.).

A utiliser avec parcimonie
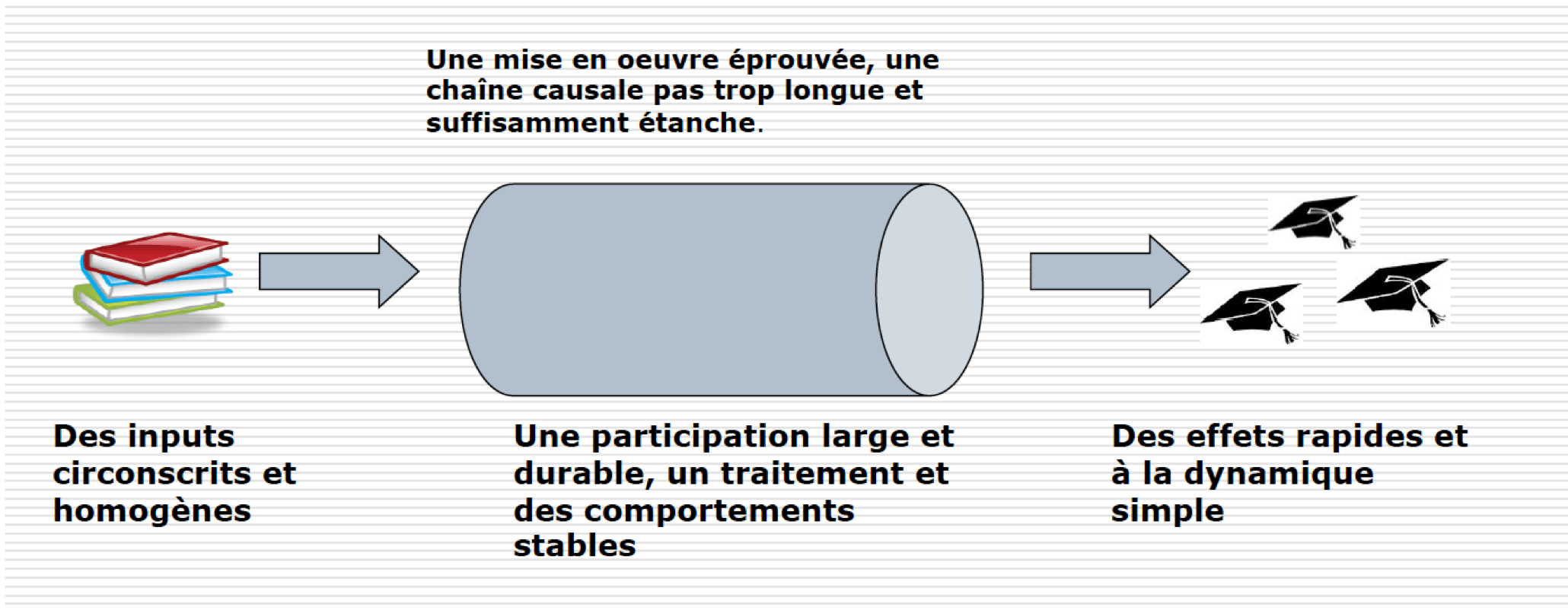
Après plusieurs expérimentations, l’AFD souligne dès 2012 l’intérêt de ce type d’approches limité à des programmes « tunnels« . En effet, pour obtenir une comparabilité et des caractéristiques identiques sur le temps du projet seront nécessaires :
- des ressources prédéfinies et stables
- une chaine de résultats peu sensible aux modifications de l’environnement
- un traitement stable (c’est à dire que le bénéfice pour le participant doit rester constant => s’autoriser une amélioration de la prise en charge en cours de route biaise l’étude)
- une cohorte de bénéficiaires constante et conséquente, à suivre sur la durée de l’évaluation
- des effets visibles et rapides (la plupart des RCT restent sur des temps relativement courts, environ 2 ans)
Les limites et points de vigilances dans la mise en place de RCT :
- La maitrise de la complexité et l’appropriation des protocoles de recherche à travers toute la chaine de collecte de données : chercheurs, traducteurs, superviseurs, enquêteurs,…
- La détection de disparités de mise en oeuvre :
La mise en oeuvre a-t-elle été distincte d’une région à l’autre ? D’une école à l’autre ? D’une ONG à l’autre, etc. ? En quoi la différence dans l’impact détecté ne serait-il pas simplement du à une différence de mise en oeuvre ?
- La capacité à maintenir la rigueur méthodologique sur la durée :
Sur quelle période le financement est-il garanti ? Quelle stabilité politique ou sécuritaire de la zone étudiée ? Une réorientation stratégique pourrait-elle affecter la mise en oeuvre et par conséquent l’objet de la recherche initiale et la fiabilité du protocole ?
Attention à la transposition des résultats
Ce qui était valable dans un contexte ne le sera bien sûr pas forcément dans un autre. Par ailleurs le changement d’échelle (le passage de l’expérimentation à l’essaimage) affectera certaines variables et leur reproductibilité. Au vu du coût élevé de ce type d’évaluation, c’est une limite sérieuse.
A titre illustratif, l’évaluation suivante « Les effets de l’internat d’excellence de Sourdun sur les élèves bénéficiaires : résultats d’une expérience contrôlée« publiée en 2012 par J-Pal et l’IPP a duré 3 ans pour un coût total de 750000€.
La première limite à cette évaluation selon les auteurs :
« Cette étude nous apprend donc quels sont les impacts d’une scolarité à l’internat d’excellence de Sourdun, mais ne nous dit rien sur les effets produits par les autres internats. Extrapoler les impacts de Sourdun semble d’autant plus hasardeux que les populations d’élèves visés et les modes de fonctionnement varient fortement d’un internat à l’autre (Rayou et Glassman, 2012). «
Des RCT cependant à systématiser pour toute élaboration de politiques publiques
Les RCT ont été présentées comme un gold standard en matière d’évaluation, mettant la barre beaucoup trop haute pour une majorité d’interventions. Des programmes de tailles moyennes se sont dispersés, visant la rigueur scientifique pour un éventuel appui à la prise de décision à long terme plutôt qu’une amélioration en temps réel au bénéfice des populations.
Effectivement, les RCT coûtent chers. Mécaniquement, par la mobilisation d’une masse salariale de plusieurs chercheurs sur plusieurs années. Mais une goutte d’eau à l’échelle de politiques publiques.
Par exemple, en France, la réforme des rythmes scolaire de 20141 (dont l’objet était de mieux prendre en compte le rythme de l’enfant et lutter contre l’échec scolaire) et progressivement abandonné depuis aurait sans doute bénéficié d’une évaluation expérimentale d’ampleur et profonde de type RCT en amont de la mise en oeuvre.
Les essais randomisés contrôlés : en bref
L’Essai Randomisé Contrôlé (ERC) est une méthode d’évaluation rigoureuse visant à mesurer les effets strictement attribuables à une intervention en comparant un groupe bénéficiaire avec un groupe témoin.
Ce type de recherche comprend diverses limites : coûts élevés, complexité méthodologique, difficultés à maintenir la rigueur scientifiques nécessaire sur la durée sur un terrain « vivant », à transposer les résultats à d’autres terrains ou encore une incapacité à détecter des effets imperceptibles, des signaux faibles en raison d’échantillons statistiques conséquents.
Les ERC offrent une validité supérieure, des preuves statistiques inatteignables par des enquêtes classiques, raison pour laquelle elle a parfois été qualifiée d’étalon d’or.
Pourtant, elle n’est qu’une méthode d’évaluation parmi d’autres. Inaccessible financièrement et techniquement pour une majorité de projets et programmes à l’échelle des territoires, ces essais mériteraient cependant être systématisés à l’échelle de la conception de toute politique publique.
Pour aller plus loin
- Antagonismes entre RCT et M&E : un enjeu opérationnel et éthique, atelier de formation sur l’évaluation d’impact, UNFPA, Banque Mondiale, rapport de fin de mission, Sébastien Galéa, avril 2017
- Fiche de synthèse, l’essai randomisé contrôlé, TIESS, 2018
Articles/études
- L’étalon-or des évaluations randomisées : économie politique des expérimentations aléatoires dans le domaine du développement, Papiers de Recherche AFD, F. Bédécarrats, I. Guérin, F. Roubaud, mai 2017
- Les évaluations d’impact dans le domaine du développement, Etat des lieux et nouveaux enjeux, Stéphanie Pamies-Sumner, Département de la Recherche, AFD, juin 2014
- Évaluations d’impact : un outil de redevabilité ? Les leçons tirées de l’expérience de l’AFD, J.D. Naudet, J. Delarue, T.Bernard, Revue d’économie du développement, 2012
- World Bank Group Impact Evaluations Relevance and Effectiveness, World Bank, 2012
- Nouvelle économie du développement et essais cliniques randomisés : une mise en perspective d’un outil de preuve et de gouvernement, Agnès Labrousse, Revue de la régulation, 1er semestre, Spring 2010
- The Limits of Nonprofit Impact: A Contingency Framework for Measuring Social Performance , Alnoor Ebrahim, V. Kasturi Rangan, working paper, Harvard Business School, May 2010
- When will we ever learn? Improving Lives Through Impact Evaluation – Center for Global Development – 2006, The Evaluation Gap Working Group, William D. Savedoff, Ruth Levine, and Nancy Birdsall, co-chairs
Extrait :
« Chaque année, des milliards de dollars sont engagés sur des milliers de programmes visant l’amélioration de la santé, de l’éducation et autres enjeux sociaux des pays du sud. Très peu d’études néanmoins cherchent à comprendre si ces programmes ont véritablement fait bouger les choses. Cette absence de preuve est un problème urgent: hormis le gaspillage de ressources, c’est un déni de soutien aux populations pauvres pour l’amélioration de leurs conditions de vie. Ce rapport réalisé par le « Evaluation Gap Working Group » affronte les lacunes de l’évaluation, réunit les preuves de ce qui fonctionne dans les programmes de développement et démontre qu’il est possible d’améliorer l’efficience de l’aide publique au développement en collectant ces informations indispensables au service de l’élaboration des politiques et des programmes de développement. »
When will we ever learn ? Improving lives through impact evaluation, 2006
Guides méthodologiques
- Comment évaluer l’impact des politiques publiques ? Rozenn Desplatz, Marc Ferracci, France Stratégie, septembre 2016
- Impact Evaluation in Practice, 2nd edition, Gertler, Paul J, Martinez Sebastian, Premand, Patrick, Rawlings, Laura B., Vermeersch, Christel M. J., Washington DC, Inter-American Development Bank and World Bank, 2016
- L’évaluation d’impact en pratique, Banque Mondiale, Paul J. Gertler, Sebastian Martinez, Patrick Premand, Laura B. Rawlings, Christel M. J. Vermeersch, 2011
- Impact Evaluations and Development, NoNIE Guidance on Impact Evaluation, Frans Leeuw, Maastricht University, Jos Vaessen, Maastricht University and University of Antwerp, 2009

De nombreuses interventions de développement semblent ne laisser aucune trace d’un changement positif ou durable et il est difficile de déterminer dans quelle mesure ces interventions font une différence. Pour cette raison, les évaluations d’impact dans l’aide au développement ont bénéficié d’une attention particulière au cours de ces dernières années. Ce document a été élaboré par le Réseau des réseaux sur l’évaluation d’impact dans le cadre d’un partage de méthodes visant à promouvoir la pratique de l’évaluation d’impact.
Ou encore :
3IE (International Initiative for Impact evaluations)

The Strategic Impact Evaluation Fund (SIEF)

Development innovation ventures (USAID)

J-PAL

Date de première diffusion : 2017
Dernière actualisation : 2024
Sébastien Galéa
Retour sur les méthodes et outils
- Capitalisation d’expérience
- Enquêtes CAP
- Etude monographique
- Evaluations d’impact
- Gestion Axée sur les Résultats
- Photovoice
- Recherche action
- Rapport d’information SENAT, un coût estimé à plus d’un milliard d’euros n’ayant fait l’objet d’aucune évaluation ni en amont ni en aval de la réforme par les services de l’état ↩︎